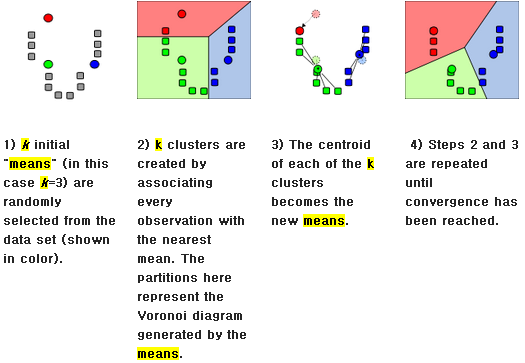
1. K-평균 군집화 (K-Means Clustering)
K-평균 군집화는 다음과 같은 과정을 통해 군집을 형성합니다.
- 초기 군집 중심 선택: $K$개의 군집 중심 $\mu_1, \mu_2, \ldots, \mu_K$를 초기화합니다.
- 군집 할당: 각 데이터 포인트 $x_i$를 가장 가까운 군집 중심에 할당합니다. 이는 다음과 같이 표현됩니다:여기서 $c_i$는 데이터 포인트 $x_i$가 할당된 군집의 인덱스입니다.
$$
c_i = \arg\min_{k} | x_i - \mu_k |^2
$$ - 군집 중심 업데이트: 각 군집의 중심을 업데이트합니다. 새로운 군집 중심은 다음과 같이 계산됩니다:여기서 $N_k$는 군집 $C_k$에 속하는 데이터 포인트의 수입니다.
$$
\mu_k = \frac{1}{N_k} \sum_{x_i \in C_k} x_i
$$ - 수렴 조건: 군집 중심이 더 이상 변화하지 않거나, 변화가 미미할 때까지 2번과 3번 과정을 반복합니다.
* 어떻게 이러한 것이 가능한가요?
클러스터 중심을 업데이트하는 과정이 효과적인 이유는 주로 다음과 같은 원리에 기반합니다:
최소화된 거리: 클러스터링의 목표는 각 데이터 포인트가 가장 가까운 클러스터 중심에 할당되도록 하는 것입니다. 클러스터 중심을 업데이트할 때, 각 클러스터에 속하는 데이터 포인트들의 평균을 계산함으로써, 해당 클러스터의 중심이 데이터 포인트들과의 거리를 최소화하도록 조정됩니다. 이는 유클리드 거리와 같은 거리 측정 방법을 사용하여 이루어집니다.
수렴성: 클러스터 중심을 반복적으로 업데이트하면, 클러스터 중심이 점차 안정된 위치로 수렴하게 됩니다. 초기 중심에서 시작하여 각 반복마다 중심을 조정함으로써, 클러스터 중심은 데이터의 분포에 맞춰 점점 더 정확한 위치로 이동하게 됩니다. 이 과정은 일반적으로 수렴 조건이 충족될 때까지 반복됩니다.
비용 함수의 최소화: 클러스터링 알고리즘, 특히 K-평균 알고리즘은 비용 함수(예: 클러스터 내 제곱 거리의 합)를 최소화하는 방식으로 작동합니다. 클러스터 중심을 업데이트하는 과정은 이 비용 함수를 줄이는 방향으로 진행되며, 이는 클러스터의 품질을 향상시키는 데 기여합니다.
데이터의 분포 반영: 클러스터 중심을 데이터 포인트의 평균으로 설정함으로써, 각 클러스터는 해당 클러스터에 속하는 데이터 포인트들의 분포를 잘 반영하게 됩니다. 이는 클러스터가 데이터의 구조를 잘 포착하도록 도와줍니다.
이러한 원리들 덕분에 클러스터 중심을 업데이트하는 과정은 효과적이며, 클러스터링의 품질을 높이는 데 중요한 역할을 합니다.
2. 실루엣 분석 (Silhouette Analysis)
실루엣 분석(Silhouette Analysis)은 군집화의 품질을 평가하는 방법 중 하나로, 각 데이터 포인트가 얼마나 잘 군집화되었는지를 측정합니다. 실루엣 값은 -1에서 1 사이의 값을 가지며, 값이 클수록 해당 데이터 포인트가 잘 군집화되었다고 볼 수 있습니다. 또한 비지도 학습의 경우에는 판단 근거가 없기 때문에 이러한 방법을 가용합니다.
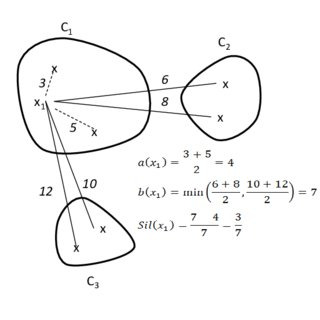
실루엣 값 $s(i)$는 다음과 같이 정의됩니다:
1. $a(i)$: 데이터 포인트 $i$와 같은 군집에 속하는 다른 모든 데이터 포인트와의 평균 거리입니다. 즉, $a(i)$는 데이터 포인트 $i$가 속한 군집 내에서의 응집도를 나타냅니다.
2. $b(i)$: 데이터 포인트 $i$와 가장 가까운 다른 군집의 데이터 포인트들과의 평균 거리입니다. 즉, $b(i)$는 데이터 포인트 $i$가 속하지 않은 군집과의 분리도를 나타냅니다.
이 두 값을 사용하여 실루엣 값을 다음과 같이 계산합니다:
$$
s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))}
$$
여기서:
- $s(i) \approx 1$: 데이터 포인트 $i$가 잘 군집화되었음을 나타냅니다.
- $s(i) \approx 0$: 데이터 포인트 $i$가 경계에 위치해 있음을 나타냅니다.
- $s(i) < 0$: 데이터 포인트 $i$가 잘못된 군집에 속해 있음을 나타냅니다.
실루엣 분석을 통해 각 데이터 포인트의 군집화 품질을 평가하고, 전체 군집화의 품질을 평균 실루엣 값으로 나타낼 수 있습니다. 평균 실루엣 값이 높을수록 군집화가 잘 이루어졌다고 판단할 수 있습니다.
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN은 밀도 기반 군집화 방법으로, 두 가지 주요 매개변수인 $\epsilon$ (반경)과 $minPts$ (최소 포인트 수)를 사용합니다.
- 핵심 포인트: 데이터 포인트 $p$가 핵심 포인트가 되기 위한 조건은 다음과 같습니다:여기서 $N_\epsilon(p)$는 포인트 $p$의 $\epsilon$ 반경 내에 있는 이웃 포인트의 수입니다.
$$
|N_\epsilon(p)| \geq minPts
$$ - 군집 형성: 핵심 포인트를 중심으로 이웃 포인트를 확장하여 군집을 형성합니다. 이 과정은 재귀적으로 진행되어 새로운 핵심 포인트가 발견될 때마다 계속됩니다.
4. Gaussian Mixture Model (GMM)
GMM은 데이터가 여러 개의 가우시안 분포로 구성되어 있다고 가정합니다. 각 군집의 확률 밀도 함수는 다음과 같이 표현됩니다:
$$
p(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x | \mu_k, \Sigma_k)
$$
여기서:
- $K$는 군집의 수
- $\pi_k$는 군집 $k$의 혼합 계수 (모든 $\pi_k$의 합은 1)
- $\mathcal{N}(x | \mu_k, \Sigma_k)$는 평균 $\mu_k$와 공분산 $\Sigma_k$를 가진 가우시안 분포입니다.
이러한 수학적 표현들은 군집화 알고리즘의 작동 원리를 이해하는 데 도움이 됩니다. 각 알고리즘은 데이터의 특성과 요구 사항에 따라 선택될 수 있습니다.
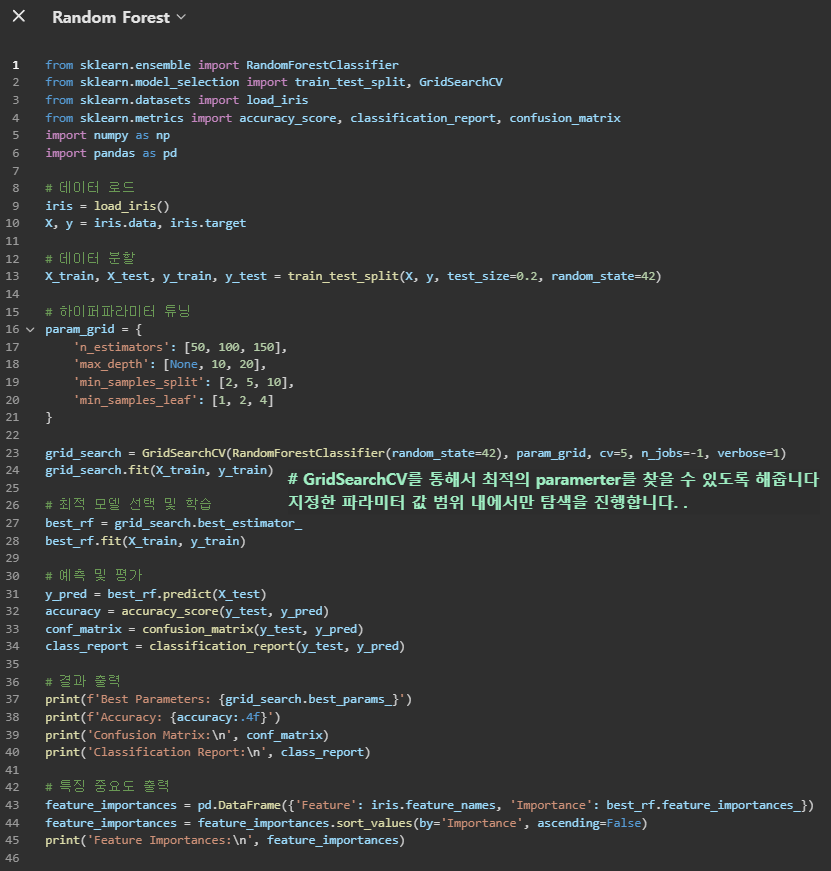
5. 구현코드
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 데이터 생성
n_samples = 300
n_clusters = 4
X, y = make_blobs(n_samples=n_samples, centers=n_clusters, cluster_std=0.60, random_state=0)
# K-means 군집화
kmeans = KMeans(n_clusters=n_clusters)
y_kmeans = kmeans.fit_predict(X)
# 실루엣 점수 계산
silhouette_avg = silhouette_score(X, y_kmeans)
print(f'평균 실루엣 점수: {silhouette_avg:.2f}')
# 군집화 결과 시각화
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='X')
plt.title('K-means 군집화 결과')
plt.xlabel('특징 1')
plt.ylabel('특징 2')
plt.show()