랜덤포레스트(Random Forest)

랜덤 포레스트(Random Forest)는 앙상블 학습 기법 중 하나로, 여러 개의 결정 트리(Decision Tree)를 결합하여 예측 성능을 향상시키는 방법입니다. 주로 분류(classification)와 회귀(regression) 문제에 사용됩니다.
랜덤 포레스트(Random Forest)는 앙상블 학습 기법 중 하나로, 여러 개의 결정 트리(Decision Tree)를 결합하여 예측 성능을 향상시키는 방법입니다. 주로 분류(classification)와 회귀(regression) 문제에 사용됩니다. 랜덤 포레스트의 주요 특징과 작동 방식은 다음과 같습니다:
1. 기본 개념
- 결정 트리: 랜덤 포레스트는 여러 개의 결정 트리를 생성하고, 각 트리는 데이터의 서브셋을 사용하여 학습됩니다. 각 트리는 독립적으로 예측을 수행합니다.
- 앙상블 학습: 여러 개의 모델을 결합하여 더 나은 성능을 얻는 방법입니다. 랜덤 포레스트는 다수결 투표(voting) 또는 평균(averaging) 방식을 사용하여 최종 예측을 결정합니다.
2. 작동 방식
- 부트스트랩 샘플링: 원본 데이터에서 중복을 허용하여 여러 개의 샘플을 무작위로 선택합니다. 각 샘플은 결정 트리를 학습하는 데 사용됩니다.
- 특성 선택: 각 결정 트리를 생성할 때, 노드를 분할할 특성을 무작위로 선택합니다. 이 과정은 트리 간의 상관관계를 줄여줍니다.
- 만약 모든 Feature를 학습하게 되면 분류기 끼리의 유의미한 특성을 만들어 내기가 쉽지 않습니다. 예를들어 키 / 몸무게 / 나이 이 세가지의 Feature을 가지고 있다고 가정해봅시다. 이렇게 세가지의 특성을 모두 학습시키는 것보다 키 - 몸무게 / 몸무게 - 나이 / 키 - 나이 이렇게 두가지로 묶어서 분류하는 것이 더 좋은 분류기를 만드는데 도움이 된다는 것입니다.
- 트리 생성: 각 샘플과 선택된 특성을 사용하여 결정 트리를 생성합니다. 이 과정은 일반적으로 깊이 제한 없이 진행되며, 과적합(overfitting)을 방지하기 위해 가지치기(pruning) 기법을 사용할 수 있습니다.
- 예측: 새로운 데이터에 대해 각 트리가 예측을 수행하고, 최종 예측은 다수결 투표(분류의 경우) 또는 평균(회귀의 경우)으로 결정됩니다.
3. 장점
- 높은 정확도: 여러 개의 트리를 결합하여 예측 성능이 향상됩니다.
- 과적합 방지: 개별 트리가 과적합되는 경향이 있지만, 앙상블 방식으로 이를 완화할 수 있습니다.
- 특성 중요도 평가: 각 특성이 예측에 얼마나 기여하는지를 평가할 수 있는 기능이 있습니다.
4. 단점
- 모델 해석의 어려움: 여러 개의 트리를 결합하기 때문에 개별 트리의 해석이 어렵습니다.
- 메모리 사용량: 많은 수의 트리를 생성하면 메모리 사용량이 증가할 수 있습니다.
- 예측 속도: 많은 트리를 사용하기 때문에 예측 속도가 느릴 수 있습니다.
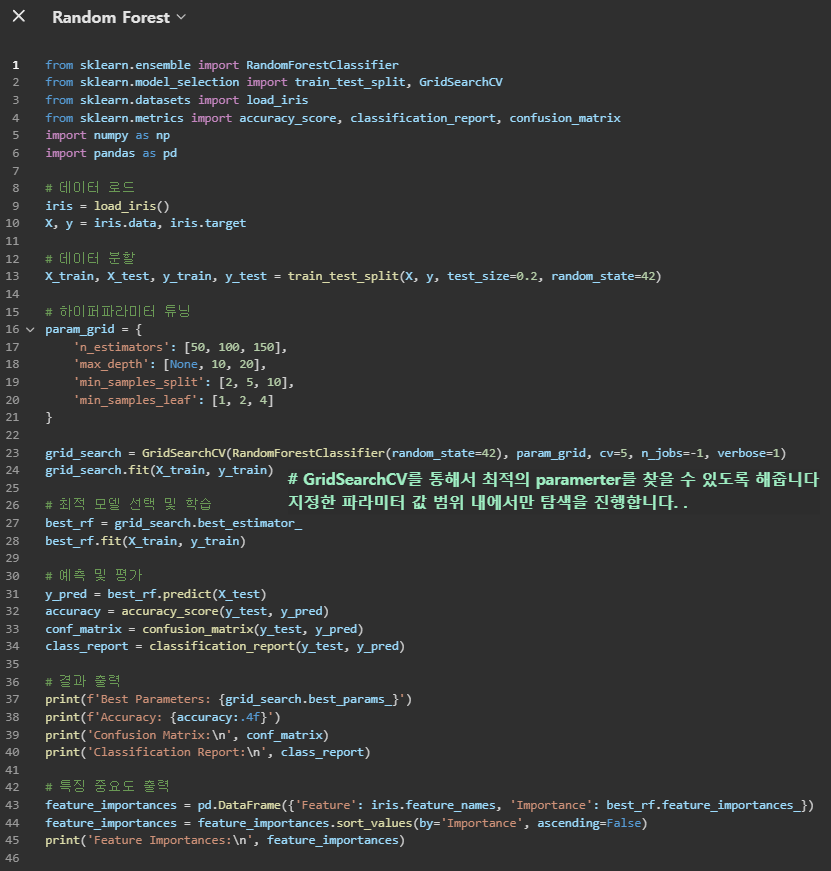
5. 코드