0. 회귀 분석(Regression)이란?
회귀 분석은 머신러닝에서 연속적인 값을 예측하는 데 활용되는 기법으로, 입력 변수와 출력 변수 간의 관계를 학습합니다. 주로 가격 예측, 수요 예측, 트렌드 분석 등에 효과적이며, 데이터의 패턴을 파악해 미래 값을 예측하는 데 강점을 가집니다. 특히, 과적합 방지를 위한 정규화 기법(L1, L2)과 배치 정규화 등을 적용하면 더욱 일반화된 모델을 만들 수 있습니다.
1. 회귀 분석(Regression) 개요
회귀 분석은 입력 변수 \( X \)와 출력 변수 \( Y \) 간의 관계를 모델링하는 과정입니다. 일반적으로 다음과 같이 표현됩니다:
$$
Y = f(X) + \epsilon
$$
여기서:
- \( Y \) : 출력 변수(종속 변수)
- \( X \) : 입력 변수(독립 변수)
- \( f(X) \) : 입력 변수 \( X \)에 대한 함수
- \( \epsilon \) : 모델이 설명하지 못하는 오차 항
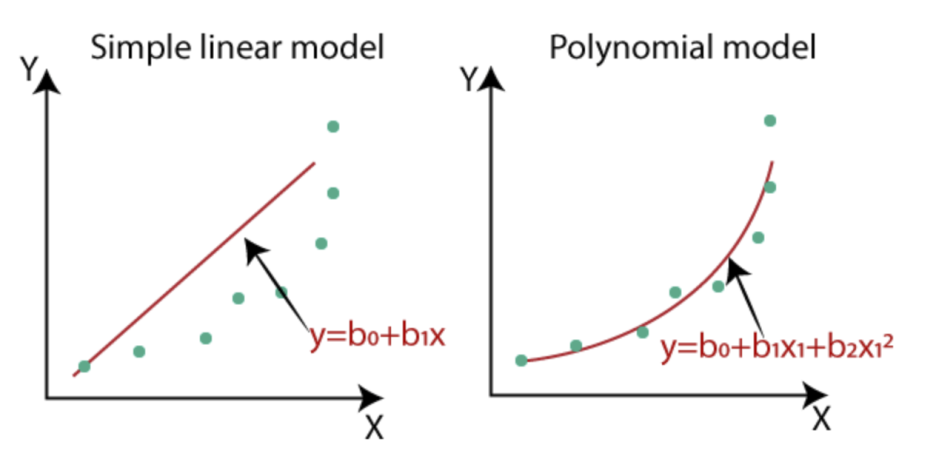
2. 선형 회귀(Linear Regression)
선형 회귀는 입력 변수와 출력 변수 간의 선형 관계를 가정하는 기법입니다.
단순 선형 회귀의 경우:
$$
Y = \beta_0 + \beta_1 X + \epsilon
$$
다중 선형 회귀의 경우:
$$
Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_n + \epsilon
$$
3. 배치 정규화 (Batch Normalization, BN)
배치 정규화는 각 층의 입력을 정규화하여 학습을 빠르고 안정적으로 만드는 기법입니다.
미니배치의 평균과 분산은 다음과 같이 계산됩니다:
$$
\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i
$$
$$
\sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2
$$
정규화 (Normalization)를 수행하면:
$$
\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}
$$
이후, 스케일링(Scale) 및 이동(Shift)을 적용하여 최종 변환을 수행합니다:
$$
y_i = \gamma \hat{x}_i + \beta
$$
4. 정규화 기법 (L1, L2 Regularization)
과적합을 방지하기 위해 사용되는 정규화(Regularization) 기법입니다.
🔹 L1 정규화 (Lasso Regression)
$$
\text{Loss} = \text{MSE} + \lambda \sum_{j=1}^{n} |\beta_j|
$$
🔹 L2 정규화 (Ridge Regression)
$$
\text{Loss} = \text{MSE} + \lambda \sum_{j=1}^{n} \beta_j^2
$$
4.5 BatchNormalization VS L1, L2 (Lasso, Ridge)
1. 목적의 차이:
- Batch Normalization: 주로 신경망에서 사용되며, 각 층의 입력을 정규화하여 학습 속도를 높이고, 내부 공변량 변화(Internal Covariate Shift)를 줄이는 데 도움을 줍니다. 이는 모델의 안정성을 높이고, 더 깊은 네트워크를 효과적으로 학습할 수 있게 합니다.
- Lasso 및 Ridge: 주로 회귀 분석에서 사용되며, 모델의 복잡성을 줄이고 과적합을 방지하기 위해 계수에 대한 규제를 적용합니다. Lasso는 L1 규제를 통해 일부 계수를 0으로 만들고, Ridge는 L2 규제를 통해 계수를 축소합니다.
2. 상호작용:
- Batch Normalization은 각 층의 출력을 정규화하여 학습을 안정화하지만, 이 과정에서 Lasso나 Ridge와 같은 규제 기법이 적용되는 방식에 영향을 줄 수 있습니다. 예를 들어, Batch Normalization이 계수를 정규화하는 방식과 Lasso 또는 Ridge가 계수에 규제를 적용하는 방식이 서로 충돌할 수 있습니다.
3. 적용 시기:
- 일반적으로 Batch Normalization은 활성화 함수 이전에 적용되며, Lasso와 Ridge는 손실 함수에 포함되어 계수에 대한 규제를 적용합니다. 이로 인해 두 기법을 함께 사용할 때는 적절한 순서와 방법을 고려해야 합니다.
4. 차이점
- 그러나 전통적인 회귀 모델(예: 선형 회귀, 다항 회귀 등)에서는 Batch Normalization을 사용할 필요가 없습니다. 이러한 모델은 일반적으로 입력 데이터의 스케일링이나 정규화가 필요할 수 있지만, Batch Normalization의 개념은 신경망의 층에서의 정규화에 초점을 맞추고 있습니다.
5. 회귀 모델의 성능 평가
✅ 평균 제곱 오차 (Mean Squared Error, MSE)
$$
\text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (Y_i - \hat{Y}_i)^2
$$
✅ 결정 계수 (R-squared)
$$ R^{2} = 1 - \frac{\sum_{i=1}^{N} (Y_i - \hat{Y}_i)^2}{\sum_{i=1}^{N} (Y_i - \bar{Y})^2} $$
여기서 \( \bar{Y} \)는 실제 값의 평균입니다.
6. 구현 코드
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, regularizers
import matplotlib.pyplot as plt
# 1. 랜덤 데이터 생성 (회귀 문제)
np.random.seed(42)
X = np.linspace(-3, 3, 300)
y = 2 * X + np.random.normal(0, 1, 300) # 노이즈 추가
# 훈련 및 검증 데이터 나누기
X_train, X_test = X[:250], X[250:]
y_train, y_test = y[:250], y[250:]
# 데이터를 (N, 1) 형태로 변환
X_train = X_train.reshape(-1, 1)
X_test = X_test.reshape(-1, 1)
# 2. 모델 생성 함수
def build_model(use_bn=False, use_l1=False, use_l2=False):
model = keras.Sequential()
# 첫 번째 Dense 레이어 (입력층)
if use_bn:
model.add(layers.Dense(64, input_shape=(1,), activation=None, kernel_initializer='he_normal'))
model.add(layers.BatchNormalization()) # 배치 정규화 적용
model.add(layers.Activation('relu')) # 배치 정규화 후 활성화 함수 적용
else:
reg = None
if use_l1:
reg = regularizers.l1(0.01) # L1 정규화 적용
elif use_l2:
reg = regularizers.l2(0.01) # L2 정규화 적용
model.add(layers.Dense(64, input_shape=(1,), activation='relu', kernel_regularizer=reg))
# 두 번째 Dense 레이어
model.add(layers.Dense(32, activation='relu'))
# 출력층
model.add(layers.Dense(1)) # 선형 회귀이므로 activation 없음
# 모델 컴파일
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
return model
# 3. 각각의 모델 생성
model_bn = build_model(use_bn=True) # 배치 정규화 적용
model_l1 = build_model(use_l1=True) # L1 정규화 적용
model_l2 = build_model(use_l2=True) # L2 정규화 적용
model_base = build_model() # 기본 모델 (정규화 없음)
# 4. 모델 학습
history_bn = model_bn.fit(X_train, y_train, epochs=100, verbose=0, validation_data=(X_test, y_test))
history_l1 = model_l1.fit(X_train, y_train, epochs=100, verbose=0, validation_data=(X_test, y_test))
history_l2 = model_l2.fit(X_train, y_train, epochs=100, verbose=0, validation_data=(X_test, y_test))
history_base = model_base.fit(X_train, y_train, epochs=100, verbose=0, validation_data=(X_test, y_test))
# 5. 학습 결과 비교
plt.figure(figsize=(12, 6))
plt.plot(history_base.history['val_loss'], label='No Regularization', linestyle='dashed')
plt.plot(history_bn.history['val_loss'], label='Batch Norm', linestyle='dotted')
plt.plot(history_l1.history['val_loss'], label='L1 Regularization')
plt.plot(history_l2.history['val_loss'], label='L2 Regularization')
plt.xlabel('Epochs')
plt.ylabel('Validation Loss')
plt.title('Effect of Batch Normalization & Regularization on Regression')
plt.legend()
plt.show()